
CCD에 이어, 전자 셔터와 글로벌 셔터에 대한 이야기를 하기 위해 쓸 노이즈에 대한 글을 위해 먼저 쓰는 이미지 센서에 대한 이야기. 이미지 센서의 대세는 CMOS 센서이기 때문에 나도 CMOS 이미지 센서에 더 관심이 많고, 그래서 CCD는 비교적 간략하게 넘어갔지만 CMOS 이미지 센서는 조금 더 자세히 설명해 보겠다. 역시 취미 수준에서는 전문적인 내용을 잘 정리해서 쓰는 것이 만만치 않다.
Photodetector와 용어에 대해서는 CCD에 대한 글을 참조하자.
3. CMOS Image Sensor (CIS)
CMOS image sensor는 트랜지스터를 이용해서 빛의 양을 측정하는 센서다. 픽셀에서 발생한 신호를 읽어내는 데 트랜지스터가 이용된다는 점이 이 이미지 센서를 규정하는 특징인데, 현재 트랜지스터는 표준적으로 CMOS 공정으로 만들어지므로 CMOS image sensor라는 이름을 갖게 되었다. 한편 동시에 이 말은 어떤 component나 구조가 CIS에 도입되기 위해서는 현행 CMOS 공정과의 호환성이 중요하다는 의미이기도 하다.
초기의 CIS는 이미지 품질이 CCD와는 상대도 안될 정도로 열악했으나, 공정 개선과 active pixel의 실용화 등으로 90년대부터 이미지 품질이 급상승하여 이제 CIS는 CCD를 밀어내고 이미지 센서의 주류로 자리잡고 있다.
CIS는 전압으로의 변환이 어디에서 일어나는가에 따라 다시 Passive Pixel Sensor (PPS)와 Active Pixel Sensor (APS)로 나뉘며, 전자는 전압 변환이 픽셀 바깥에서, 후자는 픽셀 내부에서 이루어진다. 예상할 수 있듯이, PPS의 구조가 더 단순하고 성능은 떨어진다.
3.1 Passive Pixel Sensor (PPS)
PPS는 픽셀 내에서 전압 변환을 하지 않기 때문에 다음과 같이 photodetector에 트랜지스터가 1개 달린 간단한 구조를 갖고 있다.

Passive pixel의 photodetector로는 보통 photodiode가 사용되며 (그림의 diode 모양이 photodiode다) 빛이 들어와서 발생한 photocurrent는 photodiode의 capacitance Cpd에 전하로 축적된다. PP의 유일한 트랜지스터는 신호를 읽어낼 픽셀을 선택하기 위한 스위치이며, row 라인에 전압이 가해지면 스위치가 닫히면서 Cpd에 축적된 전하가 column 라인을 통해 전압 변환기로 전달된다. 2차원으로 배치된 픽셀을 선택하는데 한 개의 스위치만이 사용되는 것이 의문일 수 있는데, 대부분의 이미지 센서들은 개별 픽셀을 선택하는 게 아니라 한 줄 단위로 선택하고 읽어낸다. 즉 특정 row를 선택하면 해당 row에 연결된 모든 픽셀들의 신호가 복수의 column 라인을 통해 병렬로 읽히는 구조로 되어 있다. 이런 병렬 동작을 위해서 픽셀 처리를 위한 자원, CDS 회로, ADC 등도 column의 수 만큼 준비되는 것이 보통이다.

- Row와 column 구성. Row select가 인가되면 해당 row의 모든 픽셀이 병렬로 읽힌다.
전압 변환기가 픽셀 바깥에 존재하고 픽셀의 전하가 변환기에 전달되어야 하므로 PPS의 신호는 CCD처럼 한 번만 읽을 수 있다 (즉, readout이 destructive 하다). PPS의 장점은 픽셀당 1개의 트랜지스터만을 사용하므로 남은 영역을 수광부에 할당하여 높은 fill factor를 달성할 수 있다는 것이다. 또한 픽셀에 전압 변환 트랜지스터가 포함되지 않으므로 이들의 차이로 인한 패턴 노이즈 (fixed pattern noise, FPN)가 active pixel에 비해 덜 나타난다는 장점이 있다. PPS에서 한 column의 픽셀은 하나의 column 전압 변환기를 공유하므로, 적어도 같은 column에 있는 픽셀끼리는 픽셀 전압 변환기의 차이에 의한 패턴 노이즈 (pixel FPN)는 나타나지 않는다. 이게 큰 장점이라고 해야 할지는 확실하지는 않은데, 픽셀간의 차이가 결과에 나타나지 않는 대신 column 전압 변환기간의 차이가 active pixel보다 더 크게 수직 패턴으로 나타나기 때문이다 (column FPN). 그 밖에 전하-전압 변환이 active pixel 내 변환보다 선형적이라는 장점이 있다.
그러나 그 이외에는 단점 투성이인데, (1) 읽기 속도가 느리고 (2) 읽기 속도, conversion gain, 그리고 full well capacity 등이 서로 얽혀 있으며 (3) read noise가 크다는 문제가 있다.
이를 조금만 더 자세히 보도록 하자. 먼저 passive pixel과 에 column read 회로까지 포함시키면 다음과 같이 된다.

Pixel 부분은 위와 동일한데 여기에 column line의 capacitance Cb와, 전압 변환 및 증폭기, 그리고 그것에 달린 buffer capacitance Cf까지 표시된 구조이다. 이제 row가 선택되어 row select 스위치가 닫히면, 전체 회로는 Cpd, Cb, Cf 로 이루어진 회로로 단순화할 수 있다. 간단히 말해서, Cpd에 있던 전하가 column line의 capacitance Cb와 전압 변환기의 버퍼 Cf로 전달되고, 변환 및 증폭되어 Vo로 출력되는 구조이다.
이 경우 PPS에서 하나의 row를 읽어내는 시간은 이 회로의 time constant를 계산하면 얻을 수 있는데, 간단히 표시하면 다음과 같아진다.
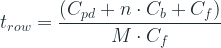
여기서 n은 센서의 row의 개수이며 M은 증폭기의 gain * 3dB bandwidth 이다 (너무 자세한 건 생략하자). 총 column capacitance는 row의 숫자에 비례하는데, 이는 row 수 만큼 Cb가 평행하게 연결되어 있는 모습을 생각하면 이해하기 쉬울 것이다. 통상적인 값을 이용해서 2048*1536 해상도의 3백만 화소 센서에 대해 계산해 보면 row당 전송 시간은 수십 us 정도로 계산된다. 이는 한 프레임을 읽어내는데만 0.0768초가 걸리는 느린 속도이다 (실제 상용 PPS는 아마 이보다 빠를 것이다. 그러나 별 의미는 없는 것이, 동일한 파라메터로 active pixel에 대해 계산하면 훨씬 더 빠르다).
그렇다면 Cpd와 Cb를 줄이고 Cf를 늘리면 전송 시간은 줄어들 것이다. 그런데 column capacitance Cb는 parasitic 성분이라 줄이기가 어렵다. Cpd를 줄이자니 full well capacity가 감소하여 픽셀이 측정할 수 있는 빛의 최대량이 감소한다. 그리고 Cf를 늘리면 conversion gain (CG), 즉 단위 광량당 (더 정확히는 빛에 의해 생성된 전자당) 전압의 변화가 감소한다 (conversion gain에 대해서는 아래에서 더 자세히 다룬다).
말하자면 전송 속도와, 센서의 이미지 품질 사이에서 이도 저도 못하는 상황이라고 할 수 있다.
사실 더 큰 문제는 readout 노이즈이다. PPS의 readout 노이즈는 대략 Cb*n에 비례하고 Cf에 반비례하며, 이는 원래도 작지 않은 column capacitance가 row 숫자에 비례해서 더 커져서 readout 노이즈를 늘린다는 이야기다. 덕분에 PPS의 readout 노이즈는 active pixel의 10배 이상으로 크며, 당연히 DR에도 큰 악영향이 있다. 그리고 센서가 고해상도가 될 수록 더 나빠지는, 상당히 안좋은 상황이 된다.
이러한 문제들을 극복하기 위한 여러 노력이 있긴 했지만 (row select 트랜지스터 구조를 개선해 본다거나, 전하 전송에 CCD-like한 구조를 도입해 본다거나, 컬럼 전압 변환기에 다른 구조를 사용해 본다거나) 그러는 동안 반도체 공정이 발전하여 active pixel을 구현할 수 있게 되자 다들 접고 active pixel로 이동하게 된다. 지금 볼 수 있는 CIS는 모두 active pixel sensor이다.
3.2 3T Active Pixel Sensor (APS)
Active pixel은 전하를 각 픽셀 내에서 전압으로 변환하는 방식이다. 전압 변환을 위해 추가적으로 트랜지스터가 픽셀에 포함되며, 다음과 같은 구조를 갖는다.

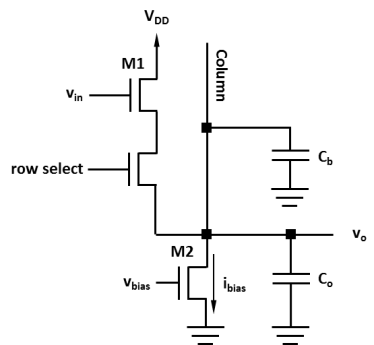
Row select를 위한 트랜지스터가 존재하는 것은 PPS와 동일하나, photodiode의 capacitance Cpd에 축적된 전하를 전압으로 변환하기 위해 트랜지스터를 추가하여 source follower 또는 common drain으로 구성한다. Source follower는 전압 버퍼 역할을 하며 gate에 가해진 전압 변화, 즉 x 지점의 전압 변화에 비례하여 y 지점에 전압 변화가 출력된다. 따라서 photodiode의 전하가 바로 column 라인으로 전달되는 대신 그에 비례하는 전압이 column 라인으로 전달된다. y지점과 x지점의 전압 변화의 비율이 source follower의 gain인데, 이 gain은 1보다 조금 작다. APS는 신호를 읽을 때 전하는 Cpd에 남아 있고 전압을 읽으므로 readout이 non-destructive 하다 (즉 신호를 여러 번 읽을 수 있다). 따라서 신호를 읽어낸 후 전하를 흘려보내야 하는데, 이러한 reset 동작을 위해 트랜지스터가 하나 더 필요하다. 따라서 총 세 개의 트랜지스터가 사용되고 3T구성이라고 부른다. 이는 APS의 가장 기본적인 구성이다.
3T APS의 동작을 조금 더 자세히 보도록 하자. 먼저 reset 스위치를 닫으면 x 지점의 전압이 VDD와 같아지고, photodiode에는 reverse bias가 걸린 상태가 된다. 이제 reset 스위치를 열고 빛이 photodiode에 도달하면 전자와 홀이 생성되어 photocurrent가 흐르고, Cpd에 전하가 축적된다. 이렇게 축적된 전하는 x지점의 전압을 낮추게 된다. 일정 시간이 흐른 후 x 지점의 전압과 VDD를 비교해 보면 얼마만큼의 빛이 들어왔는지 알 수 있다. 물론 실제로 읽는 전압은 x 지점의 전압 변화가 아니라 source follower의 gain이 적용된 y 지점의 전압 변화일 것이다.

만약 들어오는 빛이 너무 강하거나, 또는 너무 오랜 시간 동안 노출을 시키면 capacitor에 전하가 가득 차게 되고 빛이 더 들어와도 전압이 더 이상 변하지 않는다. 즉, 이 이상 밝은 빛이 들어와도 신호에 차이가 없어 밝기를 구분할 수 없게 된다. 이것이 흔히 이야기하는 화이트 홀이 생기는 원인이다. 이 때 픽셀이 저장할 수 있는 전하의 양, 즉 full well capacity는 Cpd에 의해 결정되므로 Cpd가 크면 더 많은 전하를 저장할 수 있다. 따라서 더 밝은 빛까지도 saturation 없이 밝기를 구분해서 측정할 수 있을 것이다. 그러나 3T 구성에서 Cpd는 무작정 크게 할 수는 없는데, conversion gain이 감소하기 때문이다. Conversion gain은 Cpd의 역수에 비례한다. 간단히, 10만큼의 빛이 0.1V의 전압 변화를 일으켰다면, Cpd가 2배가 되면 전압 변화는 0.05V로 줄어든다. 그리고 감소한 conversion gain은 저광량에서 SNR을 감소시킨다.
센서의 노이즈는 크게 광량에 비례하는 부분 (photon shot noise)과 일정한 부분 (read noise)으로 나뉘며, 이를 빛이 어떻게 신호로 전환되는지를 나타내는 photon transfer curve에 표시하면 다음과 같다.

x축은 입사되는 광자의 수이며, y축은 그로 인해 발생하는 신호 전압이다. Signal 선의 기울기는 QE * conversion gain 이며, 편의상 conversion gain이 변해도 QE는 변하지 않는다고 하자. 전체 노이즈는 read 노이즈와 photon shot 노이즈의 합으로 나타난다.
광량이 큰 경우, 전체 노이즈는 photon shot 노이즈가 좌우하게 되어 광량이 커질 수록 전체 노이즈도 커진다. 그러나 노이즈의 증가가 신호의 증가보다 느리기 때문에, 밝은 경우에는 노이즈 대비 신호 (SNR)는 커지게 되며, 좋은 이미지 품질을 얻을 수 있다.
광량이 작은 경우, 전체 노이즈는 read 노이즈가 좌우하게 되며, 광량에 상관 없이 일정하게 된다. 이 때 신호 전압이 작아서 read 노이즈보다 작아지게 되면 신호는 노이즈와 구분할 수 없게 되고, 신호로서 감지할 수 없다. 그러므로, 감지/구분 가능한 최저 광량은 read 노이즈를 (QE*conversion gain) 으로 나눈 값이다 (그림에서 minimum resolvable illumination 위치).
이제 conversion gain의 영향을 비교해 보자. Conversion gain이 작으면 동일 광량에서 신호 전압이 작아진다. 그런데 광량이 충분할 때는 SNR에는 별 영향이 없는데, 이는 대부분을 차지하는 photon shot 노이즈도 신호와 마찬가지로 conversion gain의 영향을 받기 때문이다. 즉, 작아진 conversion gain에 의해 줄어든 신호 전압 만큼 photon shot 노이즈가 일으키는 전압도 감소하므로 SNR에는 별로 변화가 없다.
그러나 저광량에서는 read 노이즈가 전체 노이즈를 좌우하며, conversion gain이 감소하면 신호 전압은 감소하지만 read 노이즈는 그대로이므로 SNR이 감소한다. 예를 들어 센서의 read noise가 10 uV일 때 10만큼의 빛이 들어와서 0.1V의 전압 변화가 있다면 SNR은 10000:1이지만, conversion gain이 절반이 되면 노이즈는 그대로인데 빛에 의한 전압 변화는 0.05V로 감소하고 SNR 역시 5000:1로 감소한다. 다음 그림을 보면 conversion gain이 낮은 경우가 신호 대비 노이즈가 더 크다는 것은 쉽게 알 수 있을 것이다.

또한, conversion gain이 작은 경우, 노이즈보다 더 큰 신호를 얻기 위해서는 더 큰 광량이 필요하다. 즉, 감지/구분 가능한 최저 광량이 커진다. 이는 소위 암부 DR과 계조를 감소시킨다. 따라서 Cpd를 무조건 크게 할 수는 없다.
한 가지 주의할 점은, 지금까지의 이야기는 모두 동일 픽셀 크기에서 Cpd만 변하는 경우의 이야기다. 만약 픽셀 크기가 변해서 Cpd가 달라진다면 이야기가 달라지는데, 픽셀에 들어오는 총 광량 자체가 변하기 때문이다. 다른 것이 동일하다면 photodiode의 capacitance는 photodiode의 면적에 비례하므로, 동일 기술로 만들어진 큰 픽셀은 작은 픽셀보다 더 큰 Cpd를 갖게 된다. 상황을 단순화해서 큰 픽셀은 작은 픽셀 대비 4배의 면적을 갖고 Cpd도 4배 크다고 하자. 그리고 이들을 이용해서 동일한 크기의 이미지 센서를 구성했다고 해 보자.
이 때, 큰 픽셀은 작은 픽셀보다 더 밝은 광량까지 구분해서 기록할 수 있을까? 답은 그렇다이다. 작은 픽셀이 광자 10000개에서 포화된다면, 큰 픽셀은 광자 40000개까지 포화되지 않고 신호를 구분할 수 있을 것이다.
그렇다면 큰 픽셀의 Cpd가 더 크므로, 큰 픽셀의 감지 가능한 최저 광량은 작은 픽셀보다 더 클까? 이에 대한 답도 그렇다이다. 작은 픽셀이 노이즈보다 큰 신호를 얻기 위해 10만큼의 광자가 필요하다면, 큰 픽셀은 노이즈보다 큰 신호를 얻기 위해 40만큼의 광자가 필요할 것이다.
그렇다면, 큰 픽셀로 구성된 이미지 센서는 작은 픽셀로 이루어진 이미지 센서보다 더 밝은 “장면”까지 화이트홀 없이 찍을 수 있을까? 또한, 큰 픽셀로 구성된 이미지 센서는 어두운 “장면” 을 찍는 데 작은 픽셀로 이루어진 이미지 센서보다 불리할까?
이 두 질문에 대한 답은 아니오인데, 이는 큰 픽셀은 면적이 큰 만큼 동일 “장면”에서 작은 픽셀보다 더 많은 빛을 받으며 이 늘어난 광량이 Cpd와 conversion gain의 차이를 상쇄하기 때문이다. 즉, 큰 픽셀은 4배 더 많은 광자를 저장할 수 있지만 빛도 4배 더 많이 들어오며, 감지 가능한 최저 광량이 4배 더 높지만 역시 빛도 동일 장면에서 4배 더 많이 들어온다. 이와 같이 개별 픽셀의 성능만으로는 이미지 센서의 성능을 결정할 수는 없는데, 우리가 얻는 결과 이미지는 개별 픽셀이 아니라 이미지 센서를 갖고 어떤 “장면”을 찍은 것이기 때문이다. 이 결과 이미지의 품질에는 광량이란 요소가 매우 큰 영향을 주며 개별 픽셀의 크기뿐 아니라 이미지 센서의 크기도 영향을 준다. 이에 대해서는 오해도 많고 글도 길어지므로 나중에 이 주제로 글을 별도로 쓰도록 하겠다.
3T APS의 읽기 속도는 PPS 대비 훨씬 더 빠르다. Source follower가 voltage buffer 역할을 하고 있으므로 row를 읽어내는 시간은 Cpd에 의존하지 않는다. 따라서 read out에 관계되는 부분을 픽셀 바깥까지 포함해서 다음과 같이 그려볼 수 있다.
여기서 Cb는 PPS와 동일하게 column line의 capacitance이며, Co는 읽기회로의 capacitance이다. M1이 픽셀의 source follower이며, 여기에 source follower의 biasing을 위해 M2 트랜지스터가 current source로 동작하는 구성이다. 이 회로에서 readout 시간은 row select 스위치가 닫힌 후 출력 전압이 충분히 안정화되는 데 걸리는 시간이다. Row select 스위치가 닫히면 vo의 출력 전압은 즉시 변하는 게 아니라 다음과 같이 점진적으로 안정화되며, 최종 전압에 “충분히” 근접할 때까지 걸리는 시간이 바로 row의 readout 시간이 된다.

그리고 얼마만큼 근접하는 것이 충분한지는 출력 전압 vo의 최대 swing 폭, 각 트랜지스터의 특성 (threshold 전압 등), 출력 전압이 driving 해야 하는 총 capacitance (Cb와 Co), 그리고 전압 신호를 몇 bit로 분해할 것인가 등에 영향을 받으며, 대략적으로 다음과 같이 나타낼 수 있다.

여기서 n은 PPS와 마찬가지로 센서의 row의 개수이며 k는 source follower 트랜지스터의 transconductance, 그리고 F는 bias 전류와 전압 swing 폭 등에 의해 결정되는 값이다. PPS와 비교하여 Cb와 Co에 비례하는 것은 동일하나 Cpd 항이 빠졌고, bias 전류와 transconductance가 t_row를 줄이고 있다. 앞서 계산해 본 PPS의 경우와 동일하게 2048*1536 해상도의 3백만 화소 센서에 대해 적당한 값을 넣어 보면 보면 row당 전송 시간은 수백 ns 정도로 PPS보다 월등히 빠르다.
절대 속도뿐 아니라 APS는 읽기 속도와 conversion gain 간의 trade-off도 없다. PPS에서는 charge amplifier의 capacitance Cf가 conversion gain을 결정하면서 동시에 전송 속도에 영향을 주기 때문에 conversion gain을 늘리면 전송 속도가 느려졌다. APS에서는 전송 속도는 Cpd와 무관하므로 속도에서 손해를 보지 않고 conversion gain을 적절히 설정할 수 있다. 트랜지스터가 2개 늘어나서 fill factor 면에서는 손해를 보지만 microlens가 이를 보상해 주고, 또 증가한 conversion gain은 fill factor의 손해를 메꾸고도 남는다.
그러나 3T APS도 완전하지는 않은데, 문제점 중 하나는 phododiode의 capacitance가 full well capacity 및 conversion gain과 직접 관련되어 있다는 것이다. 이는 빛을 전하로 바꾸는 부분과, 전하를 축적하고 전압으로 바꾸는 부분이 동일하기 때문인데, 이 때문에 photodiode의 디자인 자유도가 제한받게 된다. 이러한 구조는 사실 훨씬 더 큰 단점으로 이어지는데, 바로 reset 시 발생하는 kTC 노이즈를 제거하기 어렵다는 것이다.
Reset 노이즈는 photodiode를 reset 하는 과정에서 랜덤하게 남는 전하가 발생시키는데 read noise에서 상당한 부분을 차지한다. 이 노이즈는 매우 근본적인 노이즈이기 때문에 공정 개선이나 픽셀 디자인 변경으로는 줄이기 어렵다. 따라서 그 자체를 없애기 보다는 reset 시의 전압을 읽어 두고, 노출이 끝난 후 신호 전압에서 이를 빼는 방법으로 제거하는 방법이 사용된다. 신호 전압에 reset 시의 노이즈가 포함되어 있다면 거의 완전히 reset 노이즈를 제거할 수 있다. 전압을 두 번 읽기 때문에 이러한 방법을 double sampling이라고 부른다.
그런데 3T 구조는 reset이 일어나는 부분과 빛을 받아 전하를 축적하는 부분이 동일하기 때문에 reset시의 노이즈 전압을 읽어도 노출 시간 동안 이를 보관할 곳이 없다. 때문에 3T 구조에서는 먼저 노출을 시킨 후 신호를 읽고, 바로 reset을 하여 reset 노이즈를 읽어서 신호에서 빼게 된다. 이 방법은 패턴 노이즈를 제거하는 데는 효과가 있지만 신호에 포함된 reset 노이즈와 읽은 reset 노이즈는 서로 같은 reset event에서 온 것이 아니므로 (두 sample들이 서로 correlate 되어 있지 않으므로) 동일하지 않으며 따라서 reset 노이즈는 완전히 제거되지 못한다.

이렇게 제거되지 못한 reset 노이즈는 noise floor를 높이며, photon transfer curve를 참조하면 특히 저광량 성능에 악영향을 줌을 짐작할 수 있을 것이다. 이러한 문제로 인해 현대적인 CIS에서 3T APS는 거의 사용되지 않는다.
3.3 4T Active Pixel Sensor
그렇다면 문제의 해결은 당연히 빛을 받는 부분과 전하를 전압으로 변환하는 부분을 분리하는 것이며, 4T APS는 바로 그렇게 3T 구조의 문제를 해결한다 (물론 언제나 말은 쉽다). 다음은 4T APS의 일반적인 구조이다.

4T 구조에서는 전하가 전압으로 변환되는 부분을 floating node (floating diffusion, FD 라고도 자주 부른다)로 분리시킨다. 빛이 photodetector에 도달하면 전하가 발생하여 축적되다가, 노출이 끝나면 축적된 전하가 floating node로 이동된다. 그리고 이동된 전하가 source follower에 의해 전압으로 변환되어 읽히는 부분은 3T와 동일하다. Floating node는 빛에 노출되지 않도록 가려져 있고 (노출이 끝난 후에 전하가 추가로 생성되면 안되므로), photodetector와 floating node 사이에는 전하의 이동을 제어하는 스위치 (transfer gate라고 한다)가 있어야 한다. 이 스위치가 4번째 트랜지스터이며 따라서 4T 구조로 불린다.
이 구조에서는 conversion gain은 floating node의 capacitance Cd에 의존하며 photodetector의 capacitance에는 의존하지 않는다. 따라서 photodetector를 설계하는 데 있어 제약 사항이 적고, photodetector와 상관 없이 적절한 full well capacity와 conversion gain을 얻을 수 있다. 그러나 무엇보다도 4T 구조의 장점은 reset 노이즈의 제거에 있다. 이것에 비하면 conversion gain 등은 오히려 사소한 이득일 뿐이며, 추가되는 트랜지스터와 floating node가 잡아먹는 면적으로 인한 fill factor의 감소도 작은 손해일 뿐이다. 4T 역시 double sampling 기법을 이용하여 reset 노이즈를 제거하는데, 3T와 달리 reset 레벨과 신호를 같은 frame에서 sampling할 수 있다는 중요한 차이가 있다. 다음 그림을 보자.

이 그림은 시간에 따른 x 지점의 전압, 즉 floating node의 전압 변화를 표시한 것이다. Transfer gate가 닫혀 있다면 노출이 진행되고 있어도 floating node에는 전압 변화가 없다. 이제 노출이 끝나기 직전에 floating node를 reset 하고, 이 reset 레벨을 컬럼 회로에 기록해 둔다. 그리고 노출을 끝내고 transfer gate를 열고 전하를 floating node에 옮긴 후 신호를 다시 읽어낸다. Reset 직후에 전하를 옮겼으므로 읽은 신호에는 reset 노이즈로 인한 신호가 고스란히 포함되어 있다. 따라서 신호에서 reset 레벨을 빼면 순수한 신호를 얻을 수 있다. Reset 레벨과 신호가 같은 프레임에서 오기 때문에 서로 correlate되어 있다고 표현하며, 이 기법을 correlated double sampling, 또는 CDS라고 한다. CIS는 CDS가 가능해지면서 비로소 이미지 품질면에서 경쟁력을 갖추기 시작했다고 할 수 있다.
4T APS의 photodetector는 전하를 모아두고 있다가 transfer gate가 열리면 전하를 온전히 floating node에 전달할 수 있어야 한다. 매우 초기의 4T 구조에서는 3T처럼 p-n junction 구조의 photodiode가 사용되었다. 그러나 photodiode는 전하를 전달하면서 saturation mode에서 subthreshold mode로 이행하기 때문에 (설명이 쉽지 않으므로 자세한 것은 생략하기로 한다) 전하 전달 효율이 떨어진다. 따라서 4T APS에는 photogate 또는 pinned photodiode가 수광부로서 사용된다.
Photogate는 CCD에서 사용된 바로 그 구조이다. 전반적으로 괜찮게 동작하지만 QE가 낮은 편이고 특히 blue영역에서 QE가 떨어진다는 문제를 동일하게 갖고 있다. 또한 표준 CMOS 공정과의 호환성이 떨어지며, 표준 공정으로 만들면 전하 전달 효율이 감소한다는 문제가 있다.
Pinned photodiode (PPD)는 interline CCD에서 사용되던 것이 CIS로 도입된 것이다. Dark current가 작다는 이점이 있으며 blue 영역 QE 문제도 없고 전하도 floating node로 효율적으로 전달된다. PPD도 표준 CMOS 공정과 호환성 문제가 있긴 하지만 다른 장점이 많아서 공정 수정이 정당화되는 듯 하다.
현대의 4T APS는 거의 모두 PPD와 조합된 구성이다. CIS뿐 아니라 CCD도 interline + PPD 구성이 주류이므로 PPD 계열이 photodetector의 대세라고 할 수 있을 것이다. PPD와 조합된 4T APS는 3T 대비 readout 속도는 동등하고 reset 노이즈와 dark current 면에서 큰 이점이 있다. 물론 증가한 트랜지스터와 floating node 덕분에 fill factor는 3T APS보다 더욱 더 감소하지만 역시 microlens가 어느 정도 보상해 주며, 다른 장점이 크기 때문에 문제가 치명적이지는 않다 (물론 치명적이지 않다는 것이지 fill factor 감소가 전혀 문제가 안된다는 것은 아니다. 연구자들과 제조사들은 당연히 이런 fill factor의 감소도 최소화하고 싶어하고, 그래서 shared pixel 개념이 나오게 되었다. 이에 대해서는 아래에 간략히 설명한다).
그러나 모든 것이 그렇듯이 4T APS도 완전하지는 않다. 그 중 하나는 global shutter의 구현이 어렵다는 점이다. 더 정확히는, 노이즈 성능을 유지하면서 global shutter를 구현하기 어렵다. 이에 대해서는 별도로 자세한 글을 쓸 예정이다. 지금 이미지 센서에 대해 정리를 하는 것도 원래는 global shutter에 대한 설명을 하기 위한 것이기도 하고. Global shutter 동작시의 대표적인 문제를 하나 예로 들면 CDS 동작이 불가능해진다. 그 이유는 잘 생각해 보면 알 수 있으리라 생각한다.
3.4 5T/6T/7T/8T… APS
여기서부터는 4T APS의 기본 구조에 기능을 추가하거나 문제를 보완하기 위해 변형을 가한 구조들이며 3T, 4T처럼 통용되는 일반 구조가 있는 것이 아니라 같은 이름이더라도 실제 구조는 다를 수 있다. 예를 들어 트랜지스터가 7개 있다면 7T APS로 불리지만 무슨 문제를 해결하기 위해 7개의 트랜지스터를 사용하는지, 그리고 그들을 어떻게 구성하는지는 연구자들마다 제각각이다. 대체적으로 읽기 속도 향상, CDS가 가능한 global shutter 구현, dynamic range 향상이나 전자식 셔터 효율 향상 등을 위해 트랜지스터를 추가한다. 이러한 구조에서는 source follower가 2단으로 사용되거나, 픽셀 내부에 신호 보관용 영역이 추가되는 등의 변형이 이루어진다. 다음은 8T APS 구조의 예시이다. 이 구조는 신호를 전압으로 보관 (“voltage domain”)하며 CDS가 가능하면서도 고효율인 global shutter를 구현하기 위해 제안된 구조이다.

Image Sensor in 110nm Technology (master’s thesis). Delft
University of Technology)
물론 이와 같이 트랜지스터가 많이 사용되는, 복잡한 구조의 픽셀은 fill factor가 크게 떨어질 수 밖에 없으므로 실제로 상용화된 이미지 센서에서 이러한 구조를 채용할 지는 미지수이다. 전통적인 구조를 지니는 (즉 front-illuminated, 표면 조사형) 센서 중 비교적 최근 제품인 소니의 36M FF 센서 (A7R과 D800에 사용된)까지도 이러한 복잡한 픽셀 구조는 보이지 않는다. 이면조사형 센서들은 회로 면적의 제약이 덜하므로 복잡한 픽셀 구조들이 사용되고 있을 지도 모르지만, 확실치는 않다. 적층형 센서라면 아예 회로를 별도로 탑재할 수 있으므로 더욱 복잡한 회로를 사용할 수 있기는 하다. 단, 이런 경우 적층된 회로는 센서 외부에 존재하기 때문에 이들을 픽셀 구조의 일부로 보기에는 무리가 있으며, 픽셀 구조 자체는 전통적인 구조에서 벗어나지 않을 가능성이 높다.
3.5 Digital Pixel Sensor (DPS)
현대의 이미지 센서는 디지털 이미징을 위해 사용되고, 모든 이미지 센서는 낮은 노이즈와 빠른 readout 속도를 지향한다. 이러한 점에서 digital pixel sensor는 모든 이미지 센서가 궁극적으로 지향하는 지점이라고 할 수 있다. Digital pixel sensor는 각 픽셀 내부에서 analog-digital 변환을 행하는 센서를 말한다. 이 센서는 각 픽셀 내부에 ADC 회로와 디지털 메모리가 존재하며, 빛을 받아 생성된 전기적 신호를 바로 디지털로 변환하여 메모리에 보관하고, 픽셀은 전압이 아닌 디지털 신호를 출력한다.

DPS는 여러 장점이 있는데, 우선 readout 과정에서 나타나는 여러 노이즈를 배제할 수 있다. 또한, 기존 센서의 경우 컬럼 단위로 ADC가 존재하여 row 단위로 신호를 읽고 digital로 변환해야 했지만 DPS의 경우 센서 전체에서 동시에 digital로 변환할 수 있으므로 readout 속도를 크게 늘릴 수 있다. 즉, 기존 센서는 ADC에서 column 단위의 병렬성을 갖지만 DPS는 픽셀 단위의 병렬성을 가지므로 훨씬 더 빠르다. Column ADC의 차이에서 기인하는 pattern noise가 없고 픽셀마다 메모리가 있으므로 global shutter와의 상성도 좋다. 또한 신호가 디지털로 보관되므로 다양한 기법을 적용하기 쉽다. 예를 들어, dynamic range 확장 기법 중에 multiple capture 기법이 있는데, 이것은 capacitor에 전하를 모으다가 capacitor가 꽉 차면 이를 어딘가에 기록해 두고 capacitor를 비운 후 다시 전하를 모으는 기법이다. Capacitor를 비운 횟수를 기록해 두면 나중에 총 전하량을 복원할 수 있으므로 capacitor의 용량보다 훨씬 더 큰 전하량까지 측정 가능하다. DPS에서는 신호가 디지털 영역에서 다루어지기 때문에 이러한 기법들을 적용하기가 기존 센서보다 더 쉽다.
그러나 DPS의 문제는 아주 명백한데, 픽셀마다 ADC와 디지털 메모리를 넣기 위해서는 트랜지스터가 매우 많이 필요하다는 점이다. 양보해서 디지털 메모리는 외부에 둔다고 해도 픽셀 크기가 상당히 커지거나 fill factor가 바닥을 치거나 또는 둘 다가 된다. 물론 적은 숫자의 트랜지스터로 ADC를 구현하기 위한 여러 제안이 나와 있고, 모든 픽셀이 ADC를 가지는 것이 아니라 픽셀 그룹이 ADC를 공유하는 등의 절충안도 있다. 또한 CMOS 공정의 미세화 덕분에 트랜지스터가 차지하는 면적은 감소하고는 있다. 그러나 현재의 디자인과 0.18 um 정도의 공정으로는 픽셀당 20-30개의 트랜지스터가 필요하며 픽셀 pitch는 10 um가 넘어가는데 fill factor는 30%에도 미치지 못한다. 비교적 대형인 풀프레임 센서도 이제 픽셀 pitch가 4-5 um에 불과하여 4T 구성도 shared pixel 디자인을 하는 상황에서 DPS는 아직은 현실성이 떨어질 수밖에 없다.
앞으로 기술이 어떻게 발전할 지는 모르겠으나, 지금까지의 추세로 보면 픽셀에 평면적으로 ADC와 메모리를 넣기 위해 고민하기 보다는 이면조사 방식으로 회로 면적을 확보하거나, 적층형으로 픽셀 외부에 필요한 회로와 메모리를 연결하는 방식으로 가는 게 아닐까 싶다.
3.6 Shared (multiplexed) Pixel Architecture
PPS에서 3T APS, 그리고 다시 4T APS로 오면서 성능은 향상되었지만 fill factor는 트랜지스터가 하나 늘어날 때마다 감소한다. 게다가 화소 수는 늘어나는데 센서 크기는 정해져 있으니 픽셀 크기는 갈수록 줄어들고 fill factor는 더욱 더 줄어들 수밖에 없다. 물론 공정을 미세화하면 트랜지스터가 작아져 fill factor는 늘어나겠지만 공정을 줄이는 데는 돈이 많이 든다. 이런 상황에서 연구자들과 제조사들은 어떻게든 fill factor를 확보하기 위해 아이디어를 내는데 바로 구성 요소들을 픽셀끼리 공유하자는 것이다.
4T APS 구성을 다시 생각해 보자. 이 구성에서는 photodetector에 전하가 우선 축적되고, 노출이 끝난 후에 이 전하를 floating node로 가져와서 전압으로 바꾸어 읽어낸다. 그렇다면 이 floating node와, source follower가 픽셀마다 하나씩 있어야 할 필요가 있을까? 어차피 전하는 photodetector에 보관되어 있고 이들은 노출이 끝나고 읽어낼 때만 사용할 텐데 말이다. 그러므로 다음과 같은 구조를 생각해 볼 수 있다.
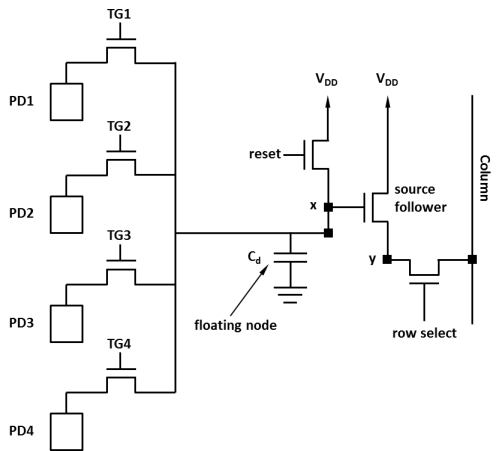
이 구조는 4개의 픽셀이 서로 구성 요소를 공유하는 경우이다. 이 구조에서 각 픽셀은 photodetector PD와, transfer gate TG만을 갖고 있고, 나머지 요소들, floating node, reset 트랜지스터, source follower와 row select 트랜지스터는 하나를 4개 픽셀이 공유한다. 이 구성의 동작은 다음과 같다. 노출이 시작되기 전, TG를 하나씩 열어 각 픽셀의 photodetector를 리셋한다. 그리고 노출이 시작되면 각 픽셀의 photodetector에는 전하가 축적된다. 노출이 끝나면 floating node를 reset 하고, TG1을 열어 전하를 floating node로 옮겨온다. 그리고 row select를 인가하여 픽셀 1의 신호를 읽어낸다 (CDS를 한다면 reset 레벨을 읽어내는 과정이 추가된다). 그리고 floating node를 reset한 후, TG2를 열어 전하를 floating node로 옮겨온다. 다시 row select를 인가하여 픽셀 2의 신호를 읽어낸다. 이를 픽셀 4까지 반복하면 4개의 픽셀을 한 조의 floating node와 source follower를 이용해서 읽어낼 수 있다.
이 구성에서는 4개의 픽셀에 총 7개 (TG 4개 + reset + SF + row select)의 트랜지스터가 사용되었으므로 평균해서 1.75T 구조라고 한다. 만약 동일한 방식으로 2개 픽셀끼리 구성 요소를 공유하면 총 트랜지스터는 5개이므로 2.5T 구조가 될 것이다. 이론적으로야 이런 식으로 6개 픽셀을 묶으면 1.5T, 8개를 묶으면 1.375T 같은 구조도 만들 수 있다. 그러나 실제로는 그만큼 읽기 속도가 느려지는데 면적 이득은 크지 않기 때문에 4개를 초과하는 수의 픽셀을 묶는 경우는 별로 없는 듯 하다. 컬러 이미지 센서의 경우 BGGR 패턴을 갖는 경우가 많으므로 2×2로 4개씩 묶는 경우가 흔히 보이지만 항상 그런 것은 아니고, 제조사에 따라 여러 종류가 있다.

- A7R과 D800에 사용된 Sony IMX094의 픽셀 이미지. Pixel 1과 2가 FD와 T3, T4, T5를 공유하는 2.5T 구성이다. T1과 T2는 transfer gate 들이고 T3는 reset, T4가 source follower, T5가 row select…인 것 같다 (아님 말고…) (source: chipworks)
이와 같은 pixel sharing 기법은 4T 구성에서만 가능하고 floating node가 없는 3T 구성에서는 쓸 수 없다. 애초에 fill factor가 감소한 이유가 4T 구성인 걸 생각하면 뭔가 병주고 약주고 같긴 하지만. 현재 대부분의 카메라용 CIS들은 pixel sharing 기법을 사용하고 있다고 보아도 된다.
다음 글에서는 여기서 설명한 내용을 바탕으로 노이즈와 전자 셔터에 대해 조금 더 자세히 써보도록 하겠다.

잘 읽고 갑니다.~ 감사합니다.
LikeLike
혼자 공부하는데 정말 많은 도움이 됐습니다. 감사합니다~
LikeLike
cis 구조에 관한 특허를 보고있는데 이쪽분야 전문가가아니라서.. 많이 도움됐습니다. 더 여쭤보고싶은게 있는데 혹시 괜찮으시면 아래 이메일로 연락부탁드립니다. 감사합니다.
LikeLike
감사해여 ㅜㅜㅜㅜ
LikeLike
좋은 글 잘보았습니다.
LikeLike
안녕하세요! 올려주신 내용 너무 잘 봤습니다. 한가지 질문하고 싶은게 있어서 문의 드립니다.
글 중간에 픽셀 면적을 키울 경우 어떻게 되는지 표현한 내용중에, ‘큰 픽셀은 노이즈보다 큰 신호를 얻기 위해 40만큼의 광자가 필요할 것이다.’ 이 대목에서 4배 커진 픽셀에서 노이즈도 4배 커지는게 맞나요? 신호와 최저 감지 광량을 나타낸 그래프를 통해 이해한 것은 최저 감지 광량의 의미가 read noise와 만나는 지점으로 이해하였거든요.
LikeLike
감사합니다 도움많이되었습니다
LikeLike
CIS 구조에 대해 이해하기 쉽게 잘 설명해주셔서 도움이 되었습니다.
감사합니다.
LikeLike
CIS이해에 정말 큰 도움이 되었습니다. 감사합니다.
위와 동일한 질문이 있는데요, ‘큰 픽셀은 노이즈보다 큰 신호를 얻기 위해 40만큼의 광자가 필요할 것이다.’ 라는 대목에서 큰 픽셀이 노이즈보다 큰 신호를 얻기 위해 필요한 최소 광자가 40이고, 작은 픽셀은 노이즈보다 큰 신호를 얻기 위해 필요한 최소 광자가 10이므로 큰 픽셀이 작은 픽셀에 비해 최저 광량을 얻기가 어려울 것으로 이해했는데 맞을까요?
LikeLike
그렇지만 큰 픽셀이 작은 픽셀에 비해 얻는 광량이 같은 조건에서 클 수 밖에 없으니 최저 광량을 얻기가 더 어렵다고 보기는 어려울 거 같아요
LikeLike
Great!
LikeLike